






若tesseract无法识别出结果,可用Pillow进行对比或亮度处理
pytesseract可以识别多种格式,如:tiff,pdf,jpg,png等
安装相关套件
在Windows 或Linux系统的命令行(不是在Python的IDLE界面里!!!)输入以下内容安装相关套件:
pip install pillow
pip install pytesseract

再安装辅助软件:Tesseract-OCR(稳定版) 最新版
#记得辅助软件的安装路径:C:\Program Files\Tesseract-OCR
#安装时要挑选中文语言包才能识别中文(不过经常断线,还是老老实实下载语言包吧。。。)
或者按此连结下载语言包资料(一定记得把chi开头的全下载)存至路径C:\Program Files\Tesseract-OCR\tessdata
在命令行里执行:pip show pytesseract
找到pytesseract的安装路径(在location那一行),复制到资源管理器的地址栏打开
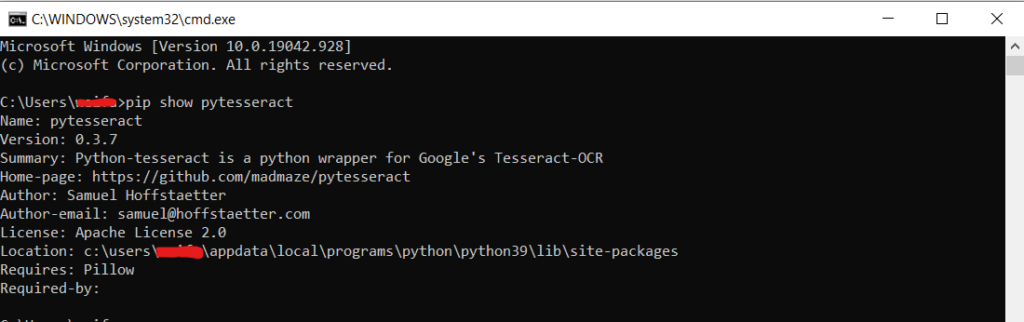

找到pytesseract模组里的pytesseract.py文件,用Python IDLE或者notepad++、Visual Studio等编辑器进行修改
找到:tesseract_cmd ='tesseract'
改成:tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
tesseract_cmd所带来的值其实就是tesseract的安装路径
英文字图片辨识


import pytesseract
from PIL import Image
image = Image.open(r'这里填写图片在本机的地址') #例如"E:\aaa\pic.jpg" 如果你的图片放在此程序文件同一个文件夹的话,直接填图片名称即可,如pic.jpg
code = pytesseract.image_to_string(image)
print(code)

中文字图片
简体中文


辨识:
import pytesseract
from PIL import Image
image = Image.open(r'这里填写图片在本机的地址') #例如"E:\aaa\pic.jpg" 如果你的图片放在此程序文件同一个文件夹的话,直接填图片名称即可,如pic.jpg (同上文英文文字识别)
code = pytesseract.image_to_string(image, lang='chi_sim')
print(code)

繁体中文
方法一样,但需将上述代码中的chi_sim改成chi_tra
The reCAPTCHA verification period has expired. Please reload the page.
Comments | NOTHING